Dedoc: система извлечения содержимого и структуры текстовых документов


Dedoc: система извлечения содержимого и структуры текстовых документов
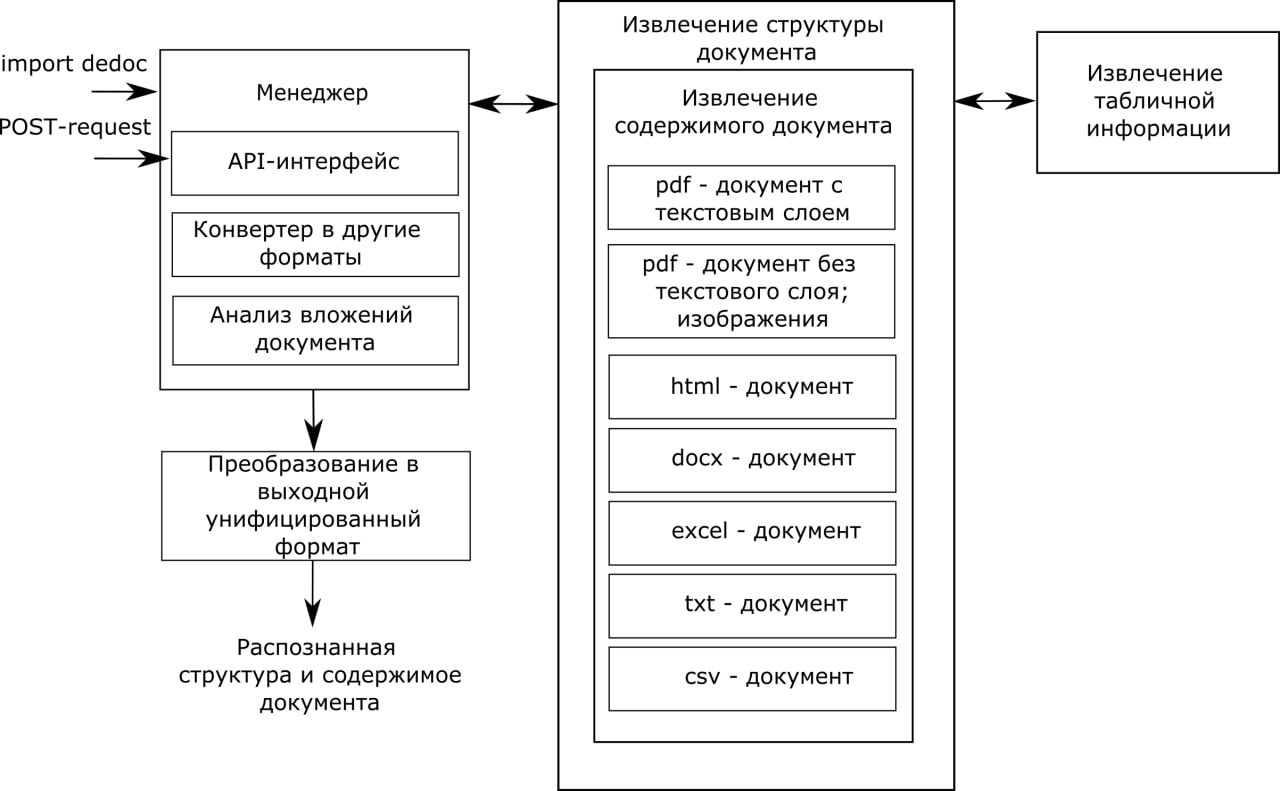
Dedoc – универсальная открытая библиотека для приведения документов к единому выходному формату. Автоматически извлекает содержимое, логическую структуру, таблицы, форматирование и метаинформацию. Содержимое документов представляется в виде дерева, кодирующего заголовки и списки различного уровня вложенности. Dedoc может встраиваться как отдельный компонент в системы анализа структуры и содержимого документов.
Особенности и преимущества
Dedoc реализован на языке Python. Работает со слабоструктурированными форматами данных (DOC*, ODT, XLS/XLSX, CSV, TXT, JSON) и с неструктурированными форматами изображений (PNG, JPG и др.), архивами (ZIP, RAR и др.), PDF, HTML. Извлечение структуры документа проводится в полностью автоматическом режиме вне зависимости от типа входных данных, с извлечением метаинформации и разного вида форматирования текста.
Dedoc – это:
- Python-библиотека c открытым исходным кодом (https://github.com/ispras/dedoc).
- Расширяемость за счёт гибкого добавления поддержки новых форматов документов и простоты изменения выходного формата данных.
- Поддержка извлечения структуры вложенных документов различных форматов.
- Извлечение разного вида форматирования текста (отступы, шрифты, жирность, размер шрифта и др.).
- Работа с документами различной предметной области (технические задания, нормативно-правовые акты, научные отчёты и статьи) и возможность добавления обработки документов новой предметной области.
- Работа с PDF-документами, содержащими текстовый слой:
- поддержка автоматического определения корректности текстового слоя.
- Извлечение табличной информации из DOC*, PDF-документов, HTML, форматов изображений, CSV:
- распознавание физической структуры и текста ячеек сложных многостраничных таблиц с границами на изображениях с помощью методов контурного анализа.
- Работа со сканированными черно-белыми документами (формата PDF без текстового слоя и с форматами изображений):
- работа с активно развивающимся движком оптического распознавания символов OCR Tesseract компании Google в совокупности с использованием методов предварительной обработки изображений;
- использование современных методов машинного обучения для определения ориентации документов, определения одно/многоколоночных документов, полужирного текста и извлечения иерархической структуры на основе классификации строк извлечённых признаков из изображений документов.
- возможность включения бинаризации для обработки документов с подложкой.
Для кого предназначена система Dedoc?
- Разработчики прикладных систем анализа содержимого электронных документов и документооборота.
- Разработчики интеллектуального анализа текста документов.
- Разработчики систем автоматической обработки текстов.
Поддерживаемые языки
Русский и английский.
Схема работы
Разработчик/участник
Перейти к списку всех технологий 