Texterra. Технология автоматического построения онтологий и семантического анализа текста


Texterra. Технология автоматического построения онтологий и семантического анализа текста
Основной сложностью семантического анализа текстов является многозначность естественного языка: одни и те же слова могут иметь различные значения в зависимости от контекста. В общем случае понимание контекста предполагает наличие базы знаний о реальном мире. При этом конструирование таких баз знаний или онтологий экспертами является чрезвычайно трудоемкой задачей.
Технология Texterra представляет инструменты для автоматического извлечения баз знаний из частично структурированных ресурсов таких, как Википедия и Викиданные, и инструменты семантического анализа текстов, использующие эти знания.
Технология Texterra находит применение в исследовательских и индустриальных проектах ИСП РАН. В частности, на основе технологии решаются такие задачи, как
- мониторинг репутации людей, организаций и товаров на основе анализа отзывов пользователей социальных медиа;
- семантический поиск документов по значениям слов;
- автоматическое построение предметно-специфичных баз знаний для задач заказчиков; например, базы данных о продуктах компании;
- и др.
Особенности технологии
Технология Texterra основывается на современных методах компьютерной лингвистики и извлечения информации. Texterra может применяться как к формальным текстам (новости, публицистика, книги), так и к пользовательскому контенту (отзывы о товарах, блоги, комментарии в социальных сетях). Основной акцент делается на два языка: русский и английский, однако с ограничениями поддерживаются и некоторые другие (например, корейский). Технология Texterra представляет собой объединение гибкой программной платформы обработки текста, коллекции модулей-расширений для нее, а также REST API, публично доступного по адресу. Данные особенности позволяют легко применять и расширять технологию для новых задач, возникающих у партнеров ИСП РАН, а также внутри ИСП РАН.
Texterra является масштабируемой технологией, благодаря своей интеграции с инструментом распределенной обработки и хранения данных Apache Ignite. Данная интеграция позволяет различным приложениям, включая приложения на базе Apache Spark, обращаться к кластерам Texterra с распределением нагрузки, а их администраторам при необходимости изменять размеры кластера без его перезагрузки и остановки обработки.
Наличие масштабируемости является критическим для технологий обработки текста в условиях быстро нарастающих объемов текстовых данных, вызванных ростом социальных медиа. На верхнем уровне технология Texterra состоит из четырех больших модулей: лингвистического анализа, базы знаний, извлечения информации, а также анализа эмоциональной окраски.
Модуль лингвистического анализа
Решение прикладных задач обработки текстов (извлечение информации, анализ эмоциональной окраски и т.п.) требует наличия качественных и производительных инструментов лингвистического анализа. Не представляется возможным понимать смысл текста без понимания его структуры и таких типовых для естественного языка явлений, как части речи или дискурс. Это и послужило причиной развития модуля лингвистического анализа в рамках технологии Texterra.
Модуль лингвистического анализа содержит в себе следующий набор методов: разбиение текста на предложения и слова; морфологический анализ, выявляющий для каждого слова в тексте часть речи, морфологические свойства, такие как род, залог, а также нормальную форму; синтаксический анализ, выявляющий для каждого предложения в тексте граф слов «родитель-ребенок», дуги которого помечаются типами связи между соответствующими словами; разрешение кореферентности, выявляющее во всем тексте кореферентные (относящие к одной сущности реального мира) цепочки слов и словосочетаний. Обработка в рамках модуля происходит поэтапно с постепенным переходом от самого низкого уровня (слова) к самому высокому (тексты).

Модуль лингвистического анализа показывает следующую производительность на одной машине Intel Core i7, 20 Gb RAM: морфологический анализ — 69000 слов в секунду; синтаксический анализ — 39100 слов в секунду; разрешение кореферентности — 10100 слов в секунду (все методы применялись к текстам без какой-либо предобработки). В связи с бурным ростом социальных медиа, тексты в которых, как правило, зашумлены, модуль также содержит метод исправления опечаток в тексте. Данный метод может служить шагом предобработки для пользовательского контента.
Модуль базы знаний
Помимо лингвистической информации о тексте для технологий анализа текстов также важна информация об окружающем нас мире, в первую очередь о сущностях (люди, организации, места, события). Нетрудно заметить, что не существует абсолютно полного источника подобной информации, однако хорошими кандидатами служат энциклопедии, такие как крупнейшая Веб-энциклопедия Википедия. Википедия содержит разделы на более чем 250 языках, причем более 10 крупнейших разделов содержат более 1 млн. статей (например, русский — 1.3 млн., английский— 5.2 млн.). Помимо текста, оснащенного гиперссылками на другие статьи, часть статей содержит и структурированную информацию (годы жизни для людей, географические координаты для мест и т.д.). В последние годы сообщество, поддерживающее Википедию, запустило новый проект Викиданные, в который энтузиасты добавляют информацию в более структурированном, нежели на Википедии, виде. База знаний технологии Texterra строится на основе Википедии и Викиданных и состоит из двух уровней: понятий и текстовых представлений. Уровень понятий — это граф. Понятиями считаются те статьи Википедии, которые прошли специальный фильтр (Википедия содержит статьи, целью которых является не описание понятия, а лишь упрощение навигации). Связи между понятиями отражают гиперссылки между статьями с пометками о специфике данной гиперссылки. К понятиям также прикрепляются различные свойства, от извлекаемых напрямую с Википедии, таких как заголовок, до извлекаемых при помощи методов машинного обучения, таких как тип сущности. Благодаря наличию у уровня понятий графовой структуры, поверх него был создан инструмент для подсчета семантической близости между понятиями. В связи с требованиями производительности данный инструмент использует лишь локальную окрестность анализируемых понятий в графе, что, однако, не препятствует получению достаточно высокой точности.
Рисунок 1. Текстовые представления (синим), связанные с ними понятия (зеленым) и семантическая близость между понятиями.
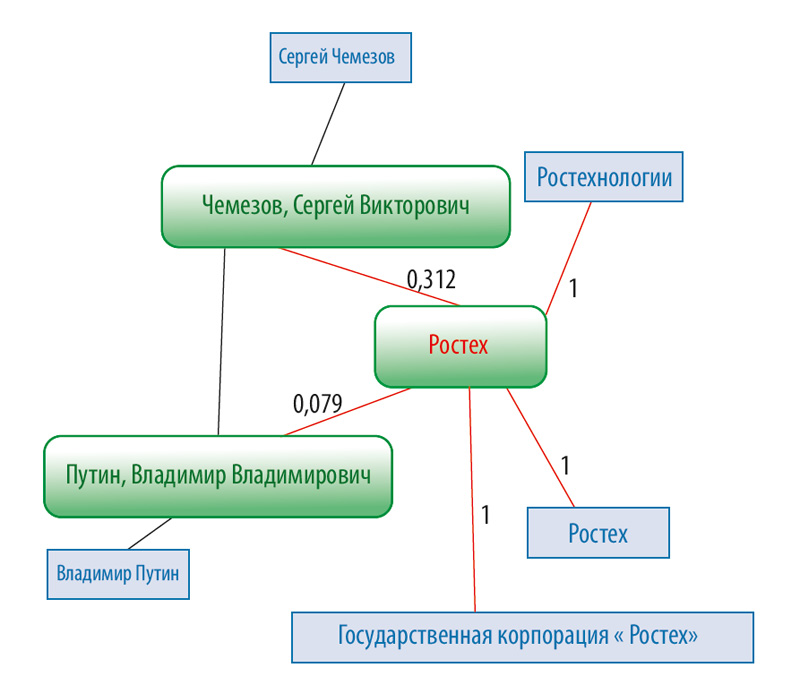
Текстовые представления (синим), связанные с ними понятия (зеленым) и семантическая близость между понятиями.
Уровень текстовых представлений содержит словарь фрагментов текста, используемых для отсылок к различным понятиям в Википедии: заголовки, высокочастотные подписи к ссылкам и т.д. Кроме того, к элементам словаря приписан набор статистик, таких как частота отсылки к различным понятиям. Важной особенностью технологии Texterra является то, что процесс построения ее базы знаний не требует привлечения экспертов, что позволяет достаточно легко переносить его на новые языковые разделы Википедии.
Модуль извлечения информации
Для приложений семантического поиска, а также приложений построения предметно-специфичных баз знаний требуются инструменты извлечения информации.
Модуль извлечения информации технологии Texterra содержит следующий набор таких инструментов: распознавание именованных сущностей (людей, организаций, событий, которые упоминаются в тексте явно, по имени), привязка фрагментов текста к понятиям базы знаний, представляющим их смысл, а также извлечение основных понятий, описывающих «общий» смысл текста.

Заметим, что методы извлечения информации могут быть достаточно легко перенесены на другие языки в случае наличия модуля лингвистического анализа и базы знаний для данных языков. Кроме того, методы извлечения информации могут применяться для расширения имеющейся базы знаний, что, в свою очередь, способно повысить их качество.
Модуль анализа эмоциональной окраски Для приложений мониторинга репутации требуются инструменты анализа эмоциональной окраски, как на уровне всего текста, так и на уровне сущности (человек, организация, товар). Модуль анализа эмоциональной окраски Texterra содержит подобные инструменты для текстов отзывов, а также сообщений социальных сетей.

Стоит отметить, что задача анализа эмоциональной окраски является зависимой от предметной области текста: оценочные слова могут иметь различную окраску в зависимости от предметной области, например, «вечный» в отношении автомобиля — это позитив, а в отношении
видеоигры — негатив. Методы анализа эмоциональной окраски Texterra учитывают данный феномен и предварительно определяют предметную область текста (также пользователь может задать ее вручную). На данный момент поддерживаются три области: тексты о политике, тексты о фильмах и произвольные тексты.
Исполнитель
Перейти к списку всех проектов 