
Texterra. Technology for automatic ontology construction and semantic text analysis


Texterra. Technology for automatic ontology construction and semantic text analysis
The basic problem of text analysis is natural language ambiguity: same words can have different meanings depending on the context. Context understanding requires knowledge bases describing real world concepts. Construction of such knowledge bases (or ontologies) is a very resource- and time-consuming task.
Texterra technology provides tools for automatic extraction of knowledge bases from partially structured resources, e.g. Wikipedia and Wikidata, and tools for analysis of texts semantics on top of these knowledge bases. Texterra technology is actively applied in research and industrial projects of ISP RAS. In particular, the following tasks are being solved by using Texterra:
- reputation monitoring for people, organizations and goods based on analysis of reviews written in social networks;
- semantic search of documents based on the meanings of words;
- automatic construction of domain-specific ontologies for partner-specific tasks;
- e.g., product databases of a company;
- etc.
Technology features
Texterra technology is based on modern methods of computational linguistics and information extraction: machine learning/deep learning in combination with classical methods if they help improve its quality. Texterra can be applied both to formal texts (news, essays, books) and to user-generated content (goods reviews, blogs, comments in social networks). The main focus is on two languages: Russian and English, even though there is limited support for some others (e.g., Korean). Texterra technology is a mix of agile software framework for text processing, a number of pluggable extensions for it and REST API which is publicly available at api.ispras.ru. These features allow you to easily apply and extend the technology for new challenges to be met both by ISP RAS partners and its departments.
Texterra is an elastically scalable technology through its integration to in-memory data storage and processing tool Apache Ignite. This integration allows different applications, including Apache Spark-based ones, work with Texterra clusters in a load balanced manner. At the same time, application administrators can easily change cluster size without restarting it and stopping data processing. Such scalability is a critical feature for text processing technologies which face fast growing volumes of text data which is provoked by social media growth.
At the highest level Texterra technology consists of four main modules: linguistic analysis, knowledge base, information extraction and sentiment analysis.
Linguistic analysis module
Solving of applied text processing tasks such as information extraction, sentiment analysis, etc. requires availability of high-quality and high-performance tools for linguistic analysis. It's nearly impossible to understand text meaning without knowing text structure and such natural language phenomena as parts of speech or discourse. This was the reason for the development of linguistic analysis module as part of Texterra technology.
Linguistic analysis module includes the following processing methods: sentence detection, tokenization; morphological analysis which extracts part of speech and grammemes (e.g., gender or voice) and canonical form for every word in text; syntactic analysis which extracts "parent-children" graph for text sentences, arcs in which link types are labeled by corresponding words (dependency grammar); coreference resolution which detects coreference chains in text (all phrases in a chain are mentions of the same entity).
Processing in the module is performed step by step from the lowest level (words) to the highest (texts).

Linguistic analysis modules have the following performance characteristics on one Intel Core i7, 20 Gb RAM box: morphological analysis – 69000 words per second; syntactic analysis – 39100 words per second; coreference resolution – 10100 words per second (all methods were applied to texts without performing any preprocessing).
Because of very fast growth of social media, which contains quite noisy texts, the module additionally exposes a method for spelling correction. This method can be used as a preprocessing step for user-generated content.
Knowledge base module
Apart from linguistic data of texts, information about real world, especially about entities (people, organizations, places, events), is quite important for text analysis technologies. It is obvious that there is no complete source of such information.
However, some encyclopedias such as Web one, Wikipedia, are quite good candidates for this role.
Wikipedia contains sections in more than 250 languages. Top ten language sections consist of more than 1 million of articles (e.g., Russian – over 1.3 million, English – over 5.2 million). Apart from texts with hyperlinks to other articles, some articles contain structured information ( lifetime for people, geographical coordinates for places, etc.).
In recent years, Wikipedia community has started a new project, named Wikidata, in which information more structured than on Wikipedia has been added by entusiasts. Knowledge base of Texterra technology is built using Wikipedia and Wikidata and contains two layers: concepts and text representations.
Concept layer is a graph. Concepts are referred as filtered Wikipedia articles (some Wikipedia articles serve for navigation purposes, not for concept descriptions).
Links between concepts are reflected by hyperlinks between articles with labels expressing hyperlinks specific features. Properties attached to concepts vary from those extracted directly from Wikipedia, such as title, to those extracted by machine learning methods, such as entity type.
Thanks to graph structure of the concept layer, a tool for semantic relatedness computation has been developed on top of it. Because of performance reasons, this tool is based on local neighborhood of analyzed concepts in the concepts graph. But this limitation doesn't impede computations of quite high precision.
Textual representation layer contains a dictionary of phrases which are exploited for mentioning different concepts at Wikipedia: titles, frequent link captions, etc.
Besides, different stats are attached to dictionary elements, e.g., frequency of mentioning different concepts.
Important feature of Texterra technology is that its knowledge base construction process doesn't require human experts, which allows quite easy porting of the process to new language sections of Wikipedia.
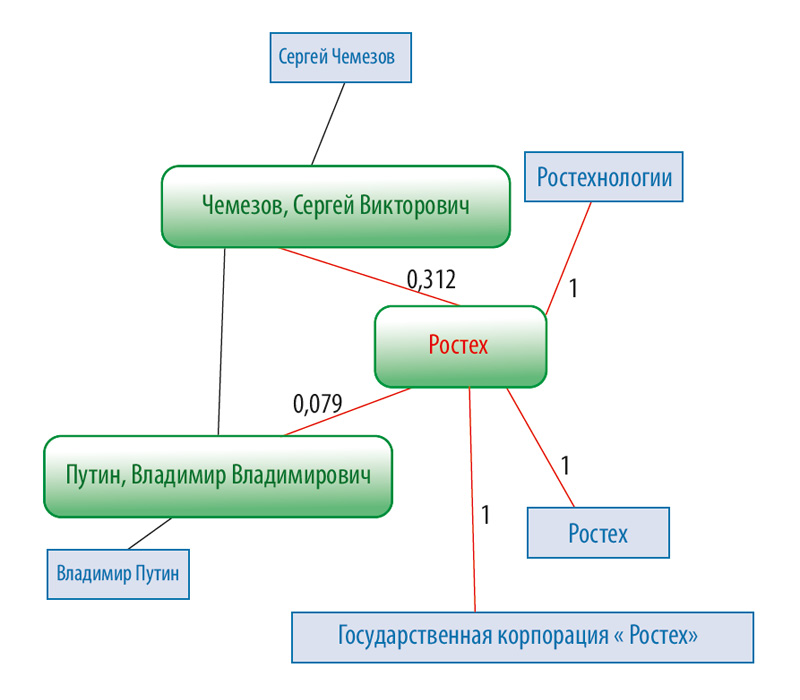
Figure 1. Textual representations (in blue), concepts linked to them (in green) and semantic similarity measure between concepts.
Information extraction module
For semantic search applications and domain-specific ontology construction application tools for information extraction are required. Information extraction module of Texterra technology consists of the following tools: named entity (people, organizations, events mentioned explicitly, by name) recognition, entity linking to knowledge base and key concepts (describing the whole text "meaning") extraction. Solution for the latter task uses fast word sense disambiguation algorithm for working with ambiguous terms: for instance, "platform" could be political, software, railway etc. depending on the context.

Note that methods for information extraction can be quite easily ported to different languages in case linguistic analysis module and knowledge base are available . Moreover, methods for information extraction can be applied for existing knowledge base extension which in turn can improve its quality.
Sentiment analysis module
For reputation monitoring applications, tools for sentiment analysis (both on text and entity levels: person, organization, good) are required. Sentiment analysis module of Texterra technology contains such tools for review texts and social networks texts.
It is important to note that sentiment analysis task is highly domain dependent: same sentiment words can have different sentiment direction in different domains, e.g., "livelong" for automobile is positive, but for video game it is negative. Sentiment analysis methods in Texterra technology are aware of this phenomena and determine text domain as a preliminary processing step (user can select it by hand too). At the moment, we support three domains: politics, movies, general.
