
Dedoc: a document structure retrieval system


Download catalogue of technologies
Dedoc: a document structure retrieval system
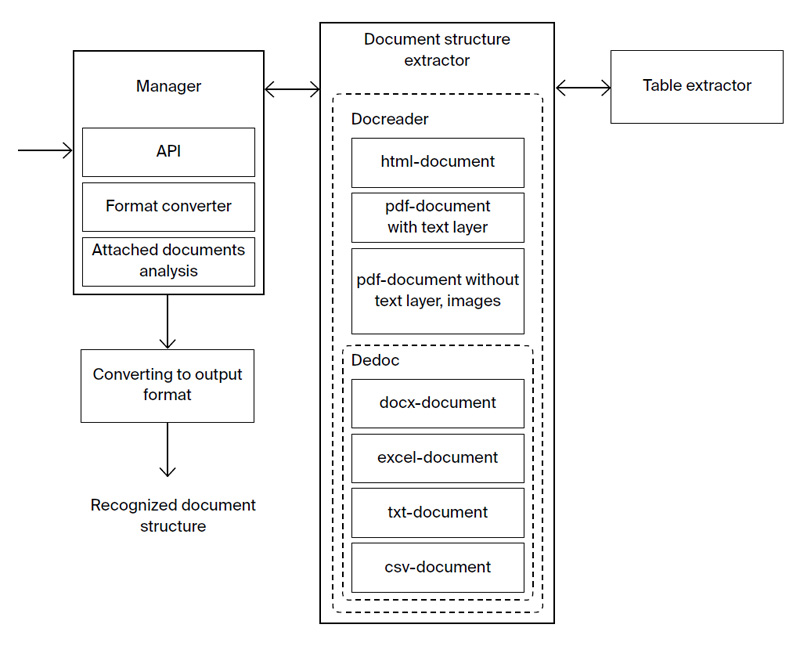
Dedoc is an open universal system for converting documents to a unified format. It extracts a document’s logical structure, its tables and metadata. The document’s contents are represented as a tree storing headings and lists of any level. Dedoc can be integrated in a document contents and structure analysis system as a separate module.
Features and advantages
Dedoc is implemented in Python and works with semi-structured data formats (DOC/DOCX, ODT, XLS/XLSX, CSV, TXT, JSON). Dedoc can be extended via plugins and contains the Docreader plugin package for working with images (PNG, JPG etc.), archives (ZIP, RAR etc.), PDF and HTML formats. Document structure extraction is fully automatic regardless of input data type. Metadata and text formatting is also extracted automatically.
Dedoc provides:
- Extensibility due to a flexible addition of new document formats and to an easy change of an output data format.
- Support for extracting document structure out of nested documents having different formats.
- Extracting various text formatting features (indentation, font type, size, style etc.).
- Adding rules for correcting mistyped document lists.
- Extracting table data from an XML-style DOC/DOCX format.
Docreader provides:
- Working with scanned document images of various origin (statements of work, legal documents, technical reports, scientific papers) allowing flexible tuning for new domains.
- Working with PDF documents either with or without a text layer.
- Recognizing a physical structure and a cell text for complex multipage tables having explicit borders with the help of contour analysis; detecting table orientation.
- Using Tesseract, an actively developed OCR engine from Google, together with image preprocessing methods.
- Utilizing modern machine learning approaches for detecting a document orientation and extracting its hierarchical structure based on the classification of features extracted from document images.
Who is Dedoc target audience?
- Developers of document contents analysis and management systems.
- Developers of intellectual text analysis algorithms.
- Developers of automatic document processing systems.
Supported languages
Russian and English.
Dedoc workflow
Developer/Participant
Back to the list of technologies of ISP RAS 